The situation often arises where an individual needs to throw away an old computer, but does not want the data on the disk of the old computer to be accessible if someone retrieves it via dumpster diving. There might still be data stored in the motherboard or some of the peripherals, but that is beyond the scope of this article. Ideally, the disk platters should be physically destroyed, but due to hardware or cost constraints, this might not always be possible.
A free way to wipe the data on the disk involves using a bootable Linux disk to write random data to the disk multiple times. Here is the general procedure:
- Boot the machine off a Live Linux disk such as Knoppix, BackTrack or Gentoo installation disk
- Identify the dev node in /dev corresponding to the disk that is to be wiped.
- Use dd to read pseudo-random data from the kernel and write it to the disk.
1) Booting off a Live Linux Disk
Live Linux disks are CDs/DVDs that a compatible computer can be booted from rather than booting from the Operating System installed on a hard disk. Live Linux disks are useful when the user wants to use the computer without leaving any trace behind, or modify the hard disks in the computer without booting the Operating System installed on them. BackTrack Linux is one such Live distribution of Linux and can be downloaded free at http://www.backtrack-linux.org/.
2) Finding the Dev Node
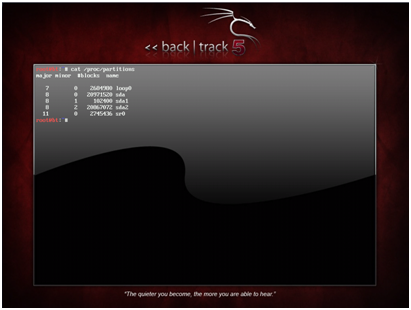
One way to find the right dev node is to match the known capacity of the disk in bytes with that reported in /proc/partitions. There should be some indication of capacity on the sticker of the disk. If not, the model number found on the sticker of the disk can be searched online and the capacity can be found that way. In Linux, both the raw disks and the filesystems on those disks appear as dev nodes in /dev. Since the goal is to wipe the whole disk rather than just a partition, the disk’s dev node rather than the partition’s dev node must be used. The disk and the partitions listed in /proc/partitions can be differentiated by looking at the last character in the name. Usually, partitions end in a digit, while disks end in a letter. The dev node to use is the file in /dev with the same name as the desired line in /proc/partitions. For example, sda refers to the first disk, while sda1 refers to the first partition on the first disk. In the example below, the computer has only 1 hard disk, sda. The sda disk has 2 partitions, sda1 and sda2. In order to wipe the disk, the /dev/sda dev node will be used.
3)Writing pseudo-random data to the disk’s dev node
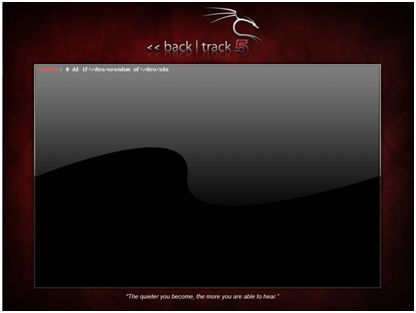
The last and most time consuming step is actually writing the pseudo-random data to the disk. The dd command is one of the standard Linux utilities, and is used for copying data. In this case, data from the /dev/urandom virtual file will be copied to the /dev/sda virtual file. In case it isn’t obvious by this point, everything in Linux is a file. The data copying will take a long time because disk I/O is relatively slow, but the operation can be tuned using the “bs=” option in dd. Once the operation is started, the hard disk activity light on the case of the computer will be on, reflecting the fact that there is a lot of disk writing occurring. Another way to check the status of the operation is to send a USR1 signal to the dd process(see the dd man page for details). A common practice relating to Gutmann’s method is to write the whole disk multiple times, so the command below can be scripted in a loop. Expect this operating to take a long time, so don’t sit around waiting for it.
By: Neil Sikka